SPSS中如何进行迅速聚类区分
发布时间:2024-05-04 文章来源:深度系统下载 浏览:
| SPSS由IBM公司出品,它提供了包括描述性统计、推断性统计、因子分析、聚类分析、回归分析等多种统计分析功能,并包括文本分析、机器学习算法、数据分析模型等。SPSS的界面友好,易于操作,能够快速从数据中提取有用的洞察和分析,广泛应用于教育、心理、医学、市场、人口、保险等多个研究领域,也用于产品质量控制、人事档案管理和日常统计报表等。 作为广受数据分析师青睐的一款数据统计和分析软件,IBM SPSS Statistics中有全面的数据分析方法,今天我们要介绍的是它的聚类分析中的快速聚类分析。 一、方法概述 聚类分析是将研究对象按照一定的标准进行分类的方法,分类结果是每一组的对象都具有较高的相似度,组间的对象具有较大的差异。 这类分析方法多用于对于数据样本没有特定的分类依据的情况,IBM SPSS Statistics会通过对数据的观察为用户做出较为完善的分类。
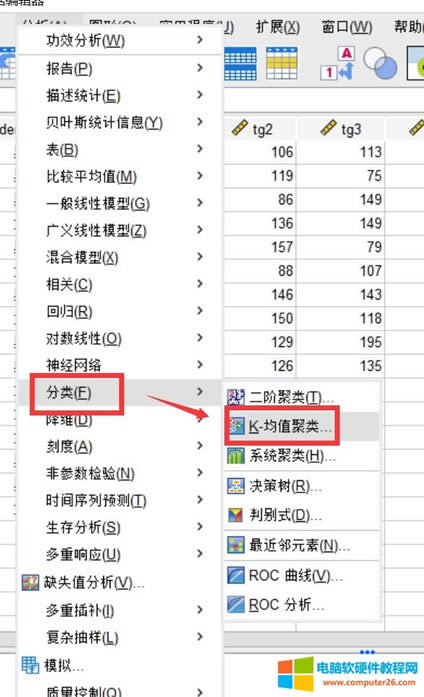
图1:功能位置 快速聚类是聚类分析的一种,使用到的功能在“分析”——“分类”中的“K-均值聚类”。 二、案例分享 1.样本数据
图2:功能位置 我们这里选择的数据样本是一部分学生的各科期末成绩,使用快速聚类方法可以分析各个学生成绩分布的差异和共性。 2.变量设置
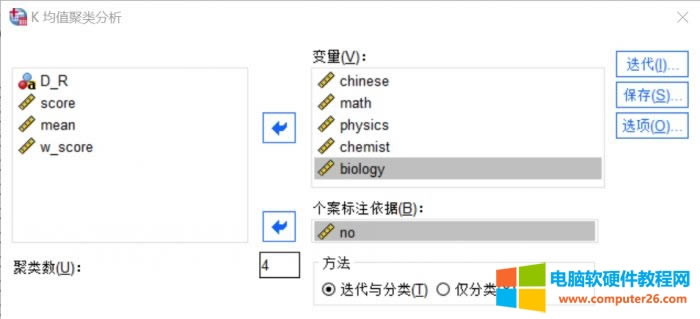
图3:功能位置 我们将学生的所有单科成绩作为分析变量,移入到“变量”窗口中,将学生的编号变量移入到下侧的“个案标记依据”窗口。 聚类数设置的是分类的数目,这个需要根据数据样本的特点来设置,我们这里设置为4类。 聚类方法有两类,即迭代和分类,前者较为复杂,会在分析过程中不断移动凝聚点,后者则始终使用初始凝聚点,我们选择两类都有的第一种分析方法。 3.聚类中心
图4:聚类中心 用户可以选择从外部文件或数据文件中写入或读取聚类中心,本案例中我们不使用这个功能。 4.迭代设置
图5:迭代设置 我们可以设置迭代的终止条件,即到达设定的最大值后将停止迭代分析,输出聚类分析结果。 收敛性标准设置的是凝聚点改变的最大距离小于初始凝聚点的比例,小于设定值时,也会停止迭代,输出结果。 使用运行均值表示每次观测后都重新计算凝聚点,这些设置保持默认即可。 5.保存
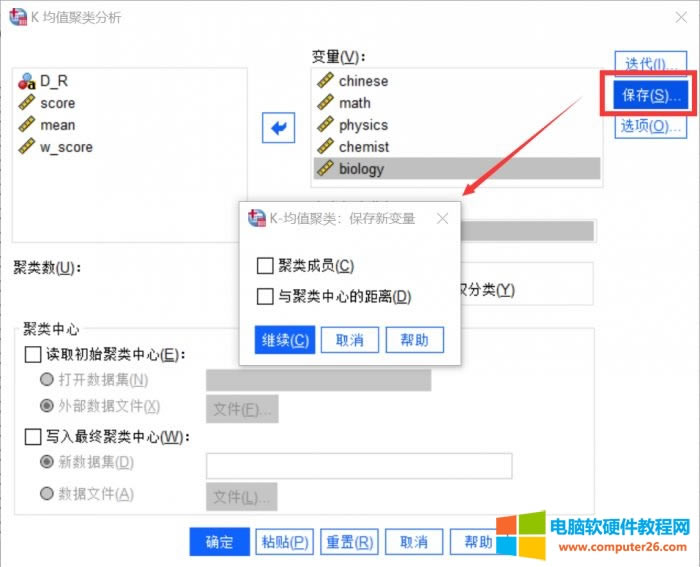
图6:保存新变量 这是用来设置保存形式的,勾选“聚类成员”将保存SPSS的分类结果,勾选“与聚类中心的距离”将保存观测值和所属类别的欧氏距离,我们不做设置。 6.选项
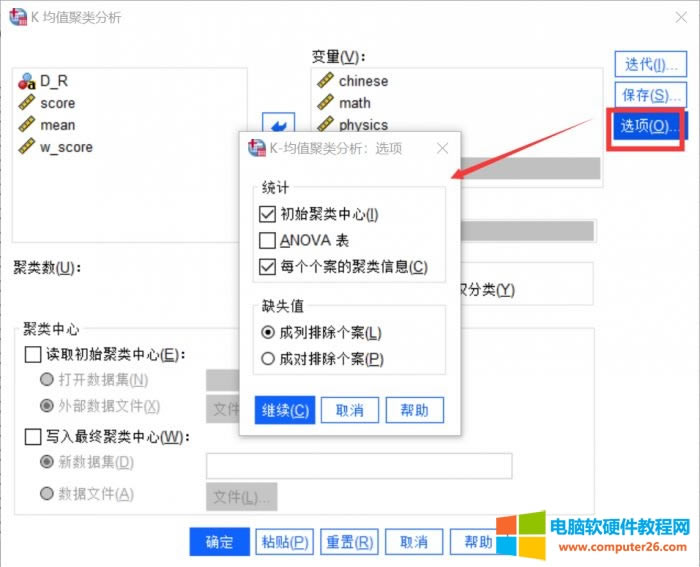
图7:选项设置 这个对话框设置的是输出的统计量和个案缺失处理方法,勾选“初始聚类中心”和“每个个案的聚类信息”。 7.结果输出
图8:聚类结果 在输出日志中可以看到,这些学生根据他们的单科成绩被分成了四类,SPSS输出了多个表格,包括初始聚类中心、迭代历史记录、聚类成员、最终聚类中心、最终聚类中心之间的距离和每个聚类中的个案数目,完整详细,可信度较高。 三、小结 使用IBM SPSS Statistics进行快速聚类的方法和案例分享就是这么多啦,这是一个较为常用的分类分析法,适用程度很高,希望可以对大家有所帮助! 世界上许多有影响的报刊杂志就SPSS给予了高度的评价。 |